Reducing jitter on Linux with task isolation
Last week I gave a talk at the first virtual adhoc.community meetup on the history of task isolation on Linux (slides, video). It was a quick 15-minute presentation, and I think it went well, but I really wanted to include some details of how you actually configure a modern Linux machine to run a workload without interruption. That’s kinda difficult to do in 15 minutes.
So that’s what this post is about.
I’m not going to cover how to use the latest task isolation mode patches because they’re still under discussion on the linux-kernel mailing list. Instead, I’m just going to talk about how to reduce OS jitter by isolating tasks using Linux v4.17+.
First, as the below chart shows, you really do need a recent Linux kernel if you’re going to run an isolated workload because years of work have gone into making the kernel leave your tasks alone when you ask.
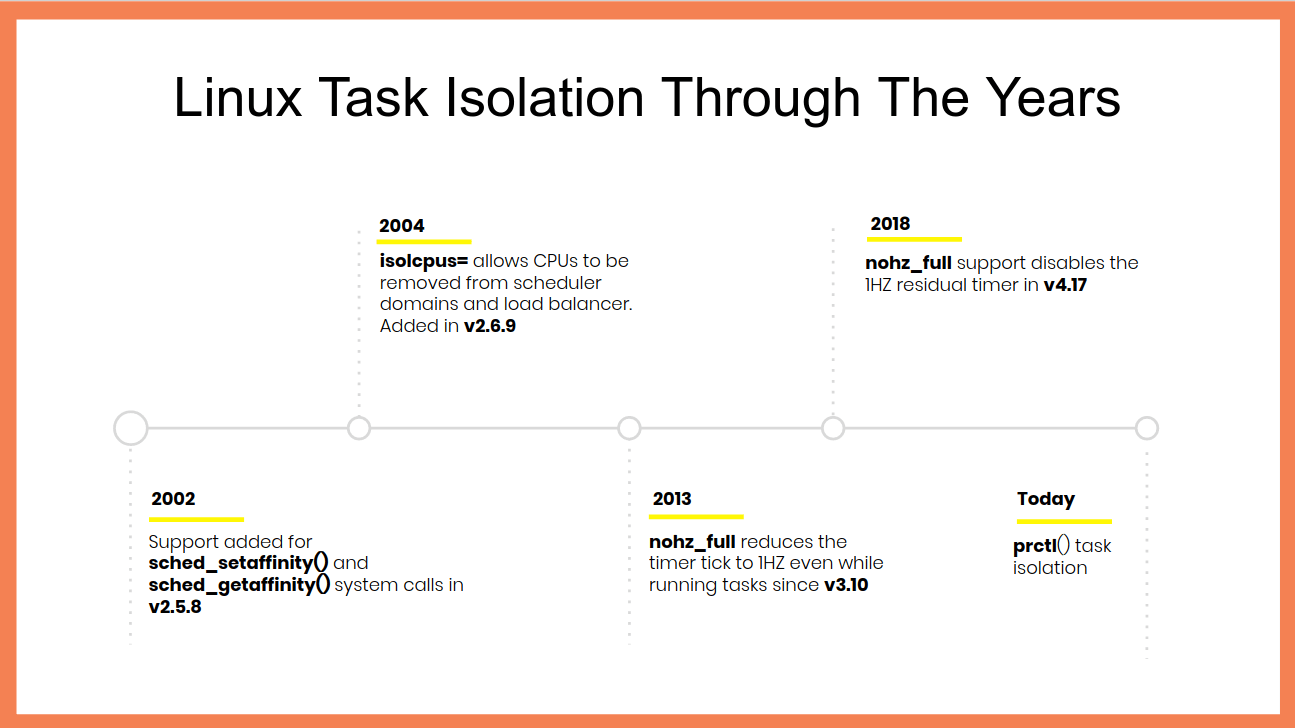 Linux task isolation features throughout the years
Linux task isolation features throughout the years
Each of these features is incremental and builds on top of the previous ones to quiesce a different part of the kernel. You need to use all of them.
Modern Linux does a pretty good job out of the box of allowing userspace tasks to run continuously once you pull the right options. Here’s my kernel command-line for isolating CPU 47:
isolcpus=nohz,domain,47 nohz_full=47 tsc=reliable mce=off
The first option, isolcpus, removes every CPU in
the list from the scheduler’s domains, meaning that the kernel will not
to do things like run the load balancer for them, and it also disables
the scheduler tick (that’s what the nohz flag is for). nohz_full=
disables the tick (yes, there’s some overlap of the in-kernel flags
which means you need both of these options) as well as offloading RCU
callbacks and other miscellaneous items.
On my machine, I needed the last two options to disable some additional timers and prevent them from firing while my task was running.
Once you’ve booted with these parameters (substitue your desired CPU
list for 47) you’ll need to setup a cpuset cgroup to run your task in
and make sure that no other tasks accidentally run on your dedicated
CPUs. cset is definitely my favourite
tool for doing this because it makes it so easy:
$ cset shield --kthread=on --cpu 47
cset: --> activating shielding:
cset: moving 34 tasks from root into system cpuset...
[==================================================]%
cset: kthread shield activated, moving 79 tasks into system cpuset...
[==================================================]%
cset: **> 56 tasks are not movable, impossible to move
cset: "system" cpuset of CPUSPEC(0-46) with 57 tasks running
cset: "user" cpuset of CPUSPEC(47) with 0 tasks runningNow all you need to do is add the PID of your task to the new user
cpuset and you’re good to go.
Verifying your workload is isolated
Of course, it’s all well and good me saying that these options isolate your tasks, but how can you know for sure? Fortunately, Linux’s tracing facilities make this super simple to verify and you can use ftrace to calculate when your workload is running in userspace by watching for when it’s not inside the kernel – in other words, by watching for when your workload returns from a system call, page fault, exception, or interrupt.
Say we want to run the following super-sophisticated workload without it entering the kernel:
while :; do :; doneHere’s a sequence of steps – assuming you’ve already setup the user
cpuset using cset – that enables ftrace, runs the workload for 30
seconds, and then dumps the kernel trace to a trace.txt
# Stop irqbalanced and remove CPU from IRQ affinity masks
systemctl stop irqbalance.service
for i in /proc/irq/*/smp_affinity; do
bits=$(cat $i | sed -e 's/,//')
not_bits=$(echo $((((16#$bits) & ~(1<<47)))) | \
xargs printf %0.2x'\n' | \
sed ':a;s/\B[0-9a-f]\{8\}\>/,&/;ta')
echo $not_bits > $i
done
export tracing_dir="/sys/kernel/debug/tracing"
# Remove -rt task runtime limit
echo -1 > /proc/sys/kernel/sched_rt_runtime_us
# increase buffer size to 100MB to avoid dropped events
echo 100000 > ${tracing_dir}/per_cpu/cpu${cpu}/buffer_size_kb
# Set tracing cpumask to trace just CPU 47
echo 8000,00000000 > ${tracing_dir}/tracing_cpumask
echo function > ${tracing_dir}/current_tracer
echo 1 > ${tracing_dir}/tracing_on
timeout 30 cset shield --exec -- chrt -f 99 bash -c 'while :; do :; done'
echo 0 > ${tracing_dir}/tracing_on
cat ${tracing_dir}/per_cpu/cpu${cpu}/trace > trace.txt
# clear trace buffer
echo > ${tracing_dir}/traceThe contents of your trace.txt file should look something like this:
# tracer: function
#
# entries-in-buffer/entries-written: 102440/102440 #P:48
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
<idle>-0 [047] dN.. 177.931485: sched_idle_set_state <-cpuidle_enter_state
<idle>-0 [047] .N.. 177.931487: cpuidle_reflect <-do_idle
<idle>-0 [047] .N.. 177.931487: menu_reflect <-do_idle
<idle>-0 [047] .N.. 177.931488: tick_nohz_idle_got_tick <-menu_reflect
<idle>-0 [047] .N.. 177.931488: rcu_idle_exit <-do_idle
<idle>-0 [047] dN.. 177.931488: rcu_eqs_exit.constprop.71 <-rcu_idle_exit
<idle>-0 [047] dN.. 177.931489: rcu_dynticks_eqs_exit <-rcu_eqs_exit.constprop.71You want to make sure that the you didn’t lose any events by checking
that the entries-in-buffer/entries-written fields have the same
values. If they’re not the same you can further increase the buffer size
by writing to tracing/per_cpu/<cpu>/buffer_size_kb.
The key part of the trace file is the finish_task_switch tracepoint
which tells you when a context switch completed. You can use this
tracepoint to find when your bash process starts running and when it
finishes – hopefully after 30 seconds has elapsed – with a bit of awk
magic:
$ awk '/: finish_task_switch / {
# Do not start counting until we see the bash task for the first time
comm = substr($1, 0, index($1, "-")-1)
if (comm == "bash") {
counting = 1;
}
}
{
if (counting) {
usecs = $4
gsub(/\./,"",usecs)
gsub(/\:/,"",usecs)
msecs = usecs / 1000
delta = msecs - last
if (last && (delta > runtime)) {
runtime = delta
}
last = msecs
}
}
BEGIN { runtime = -1 }
END { printf "Max uninterrupted exec: %.2fms\n", runtime }' < trace.txt
Max uninterrupted exec: 29877.67msI’ve successfully used this technique to verify that I can run a bash busy-loop for an hour without entering the kernel.