The Linux x86 ORC Stack Unwinder
No one wants their Linux machine to crash. But when it does, providing as much information as possible to the upstream developers helps to ensure it doesn’t happen again. Fixing the bug requires that developers understand the state of your machine at the time of the crash. One of the most critical clues for debugging is the stacktrace, produced by the kernel’s stack unwinder. But the kernel’s unwinders are not reliable 100% all of the time. The x86 ORC unwinder patch series, posted to the Linux kernel mailing list by Josh Poimboeuf, aims to change that.
The Purpose of Stack Unwinders
If your Linux machine crashes, kernel developers want to know the execution path that led to the crash because it helps them to debug and fix the root cause. A stack unwinder’s job is to figure out how a process reached the current machine instruction. This sequence is known as a stacktrace or callgraph. It is a list of functions that were entered (but not exited) on the way to the current instruction.
When a crash occurs, a callgraph is displayed in the Oops message. Here’s an example with the callgraph highlighted by a red box.
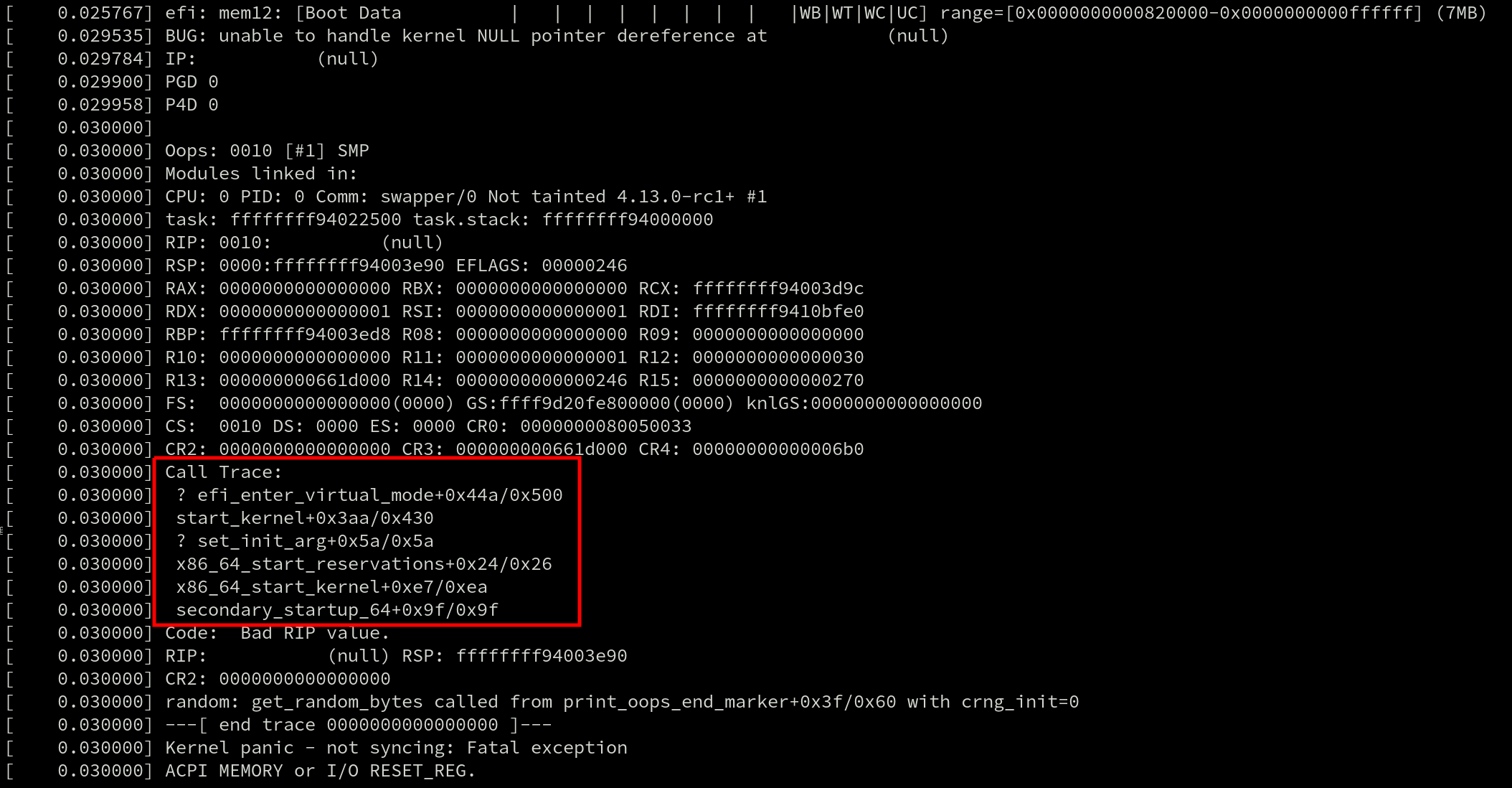
They’re also used by profilers such as perf and ftrace. Even live patching requires generating a callgraph because tasks can only be moved to the new (patched) version of a function if they’re not currently inside of the old one. And that requires searching for the function in the task’s callgraph.
Stack unwinders also exist outside of the kernel and callgraphs can be generated by debuggers like gdb for debugging live applications and to post-process coredumps.
With so many uses, there are plenty of developers that have an interest in ensuring stack unwinders work well. The two most prominent attributes of an unwinder are how quickly it can generate a callgraph, and how accurate that callgraph is.
As of Linux v4.12, there are multiple x86 unwinders: the guess and frame pointer unwinders. The guess unwinder is extremely simple and makes a guess at the callgraph by looking for instruction addresses on the stack. Its accuracy leaves a lot to be desired.
A far more robust stack unwinder is the frame pointer unwinder.
The Frame Pointer and DWARF Unwinders
The frame pointer unwinder is the current default for x86 in the mainline kernel. It requires support from the compiler which uses the rules described in the x86-64 ABI to save the address of the previous stack frame in the %rbp register at the start of every function (the prologue). When the kernel is compiled with this option the %rbp register is only used for that one purpose, and not for general use.
Stack frames are chained together by copying the value of %rbp to the current stack frame before the register is overwritten. Because the stack frames have a fixed layout – and because the function return addresses are at a known offset inside the stack frames – unwinding the stack then simply requires some arithmetic and pointer dereferencing; this is the reason that the frame pointer unwinder is so fast.
One of the downsides of the frame pointer unwinder is that using it introduces a runtime overhead for every function in the kernel. Regardless of whether a crash occurs there or not, every function prologue is modified to save the address of the stack frame in %rbp and restore the previous %rbp value in the epilogue before returning. In the cover letter for the ORC series, Poimboeuf reported that the kernel text size increases by 3.2% when GCC’s frame pointer option is enabled.
For some workloads, this overhead can be significant. Mel Gorman reported that enabling the GCC’s frame pointer option has been observed to add between 5% and 10% overhead when running benchmarks like netperf, [page allocator microbenchmark (run via SystemTap), pgbench and sqlite due to “a small amount of overhead added everywhere”. The overhead is caused by an increase in CPU cycles due to the additional instructions in every function prologue and epilogue, which bloats the kernel text size, and ultimately causes more instruction-cache misses.
The frame pointer unwinder can also have trouble unwinding a stack across the kernel-user boundary – it can be a major problem when using perf to profile an application. If the kernel was compiled with the frame pointers enabled, the application and every library it uses also needs to have been compiled with frame pointers enabled. Most Linux distributions do not compile their software with frame pointers enabled, and users have to result to building their software stacks by hand with custom compiler options if they want full callgraphs.
Finally, frame pointer unwinding is not reliable across exceptions and interrupts. Interrupts can occur at any point, including before the %rbp register has been written to. When that happens, the frame pointer unwinder is unable to calculate the callgraph. This results in inaccurate stacktraces in an Oops message, and impacts the ability to live patch which requires reliable stacktraces.
One unwinder that is reliable across interrupts is the DWARF unwinder. The DWARF unwinder generates a callgraph by parsing the DWARF Call Frame Information (CFI) tables that are emitted by the compiler.
DWARF was invented for debugging applications and callgraph generation is only a small part of that. DWARF is a very sophisticated debugging format. It can describe the state of a machine’s registers at any instruction with the use of a complex state machine.
Because the DWARF debuginfo lives in data tables the data used by the unwinder is out-of-band and can be distributed as a separate file. This is exactly what many Linux distributions do with their kernels. This completely eliminates the runtime overhead except for those users that want to debug a crash or profile a task; this is in stark contrast to the frame pointer unwinder.
The catch? There is no DWARF unwinder in the mainline Linux kernel for x86. Separate tools like gdb must be used to post-process crash dumps and generate callgraphs for kernels built with DWARF debuginfo, making it impossible to use DWARF for Oops messages, live patching, perf and ftrace.
Many years ago, there was a DWARF unwinder in the kernel but it was removed after developers discovered bugs that caused the oops code to crash – crashing inside the crash handler does not fulfill the promise of a more reliable unwinder. A recent series from Jiri Slaby that added the DWARF unwinder currently carried in SUSE’s kernel brought up a lot of the historical issues.
Some of those were caused by missing or incorrect DWARF information generated by GCC. Linus replied to Slaby’s patch and retold some of the problems with GCC’s DWARF debuginfo: “nobody actually really depended on it, and the people who had tested it seldom did the kinds of things we do in the kernel (eg inline asms etc).”
While the compiler can automatically generate the DWARF debguinfo for C code, anything written in assembly (there are over 50,000 lines in the x86 source) must be hand-annotated. Even after the original DWARF unwinder was removed, annotations remained in the x86 assembly code for years. But eventually their maintenance burden became too much and they were deleted by Ingo Molnar in during the v4.2 merge window.
Linus was clear that no DWARF unwinder would be allowed in the kernel: “Because from the last time we had fancy unwindoers [sic], and all the problems it caused for oops handling with absolutely zero_ upsides ever, I do not ever again want to see fancy unwinders with complex state machine handling used by the oopsing code.”
Enter the ORC Unwinder
It was in the middle of this discussion that Poimboeuf discussed the possibility of a new unwinder and debug format. The proposed solution is the ORC unwinder.
It creates a brand new custom debuginfo format using objtool and the existing stack validation work. The ORC format is smaller, and therefore, much simpler than DWARF which means no complex state machine is required in the unwinder.
Plus, with the format entirely controlled by the kernel community, it should provide both the reliability guarantees (no bugs in debuginfo causing crashes) and low-maintenance overhead (since it doesn’t require hand-annotating assembly code) that are missing with DWARF. Interrupts and exceptions are handled reliably with the ORC unwinder.
Like DWARF, but unlike frame pointers, the data is out-of-band and doesn’t increase the kernel text size, though Poimboeuf says enabling the ORC unwinder requires adding 2-4MB of ORC debuginfo which will increase the size of the data sections in the kernel image.
As Poimboeuf explains in his cover letter when comparing ORC and frame pointers: “In contrast, the ORC unwinder has no effect on text size or runtime performance, because the debuginfo is out of band. So if you disable frame pointers and enable the ORC unwinder, you get a nice performance improvement across the board, and still have reliable stack traces.”
The simplicity of the ORC unwinder also makes it faster. Jiri Slaby demonstrated that undwarf is 20x faster than DWARF unwinder. Performance tweaks have been added since and Poimboeuf speculates that the speed up may now be closer to 40x.
The Name
Until version v3 of the patch series the unwinder went by the name “undwarf”. After Poimboeuf said he wasn’t tied to the name, Ingo Molnar suggested some alternatives that were riffs on the ELF, DWARF tune. Poimboeuf took the Middle Earth theme and ran with it, finally settling on ORC aftering reading the Middle-earth peoples article on Wikipedia: “Orcs, fearsome creatures of medieval folklore, are the Dwarves’ natural enemies. Similarly, the ORC unwinder was created in opposition to the complexity and slowness of DWARF.” The backronym of ORC is “Oops Rewind Capability”.
How it works
All stack unwinders that use out-of-band data need some mechanism for generating that data. ORC uses objtool to build unwind tables which are built into the kernel image at link time, when a new kernel is built. The in-kernel ORC unwinder processes the unwind tables whenever a callgraph needs to be generated.
The stack validation tool is used to analyze all of the instructions in an object file and build unwind tables to describe the state of the stack for at each instruction address. This data is written to two parallel arrays, .orc_unwind and .orc_unwind_ip. Using two sections allows for a faster lookup of ORC data for a given instruction address because the searchable part of the data (.orc_unwind_ip) is more compact.
The tables consist of struct orc_entry elements, which describe how to locate the previous function’s stack and frame pointers. Each element corresponds to one or more code locations.
The existing x86 unwinder infrastructure that supports the frame pointer and guess unwinders already provides most of the code required for the ORC unwinder. As a rough measure of unwinder complexity, the number of lines of C required to implement each of the unwinders (frame pointer: 391, ORC: 582, DWARF: 1802) puts the ORC unwinder closer to frame pointer than DWARF.
Future Work
The ORC unwinder certainly shows promise. But it is still missing a few important features that will prevent it from becoming the default unwinder in the kernel.
For one, it doesn’t have stack reliability checks, which means it cannot be used with live patching. Live patching performs runtime checks and decides when it’s safe to patch a function by checking for the presence of a function in a task’s callgraph. But the improved reliability across interrupts and exceptions that ORC provides will likely make reliabilty checks a high priority item.
Support for dynamically generated code such as from ftrace and BPF is missing too.
And since ORC is an in-kernel unwinder, there is no support in the perf tool for generating callgraphs using ORC in userspace. Poimboeuf suggested that adding it should be possible: “If you want perf to be able to use ORC instead of DWARF for user space binaries, that’s not currently possible, though I don’t see any technical blockers for doing so. Perf would need to be taught to read ORC data.”
Based on the majority of comments so the ORC unwinder series so far, it seems likely that it will be merged for the v4.14 timeframe. Whether or not it will be enabled by default still remains to be seen – many developers, including Linus, vividly remember the last time a new unwinder was used in the Oops code. The hope is that orcs will prove more reliable than dwarves.